


A failover cluster is essentially a redundant, performance-optimized backup system for digital architectures. When a group of two or more independent servers is designed to work together with the purpose of providing a robust backup structure; better balancing workloads; ensuring integrity and reliability of applications, systems, or services; and providing scalability and availability, it is considered a failover cluster.
Failover clusters are used heavily by industries that need to run mission-critical applications, systems, and services. Here’s a look at how the tech works, the different types of failover clusters, their challenges, and practical applications.
Failover cluster types
There are two main types of failover clusters, high availability (HA) and continuous availability (CA), but there are other options as well, especially for hybrid failovers combining virtual and physical infrastructure.
What type of failover cluster is the best fit for your organization will depend on several factors including your infrastructure, hardware and software, the level of sophistication of your system and apps and how business-critical are your digital operations. Additionally, some industries require less latency than others. Finally, issues like in-house talent, budget and cybersecurity and compliance demands must also be evaluated.
High availability clusters
High availability (HA) clusters are designed to minimize downtime and ensure that applications and services are always available, even if one server in the cluster fails. HA clusters typically use shared storage and clustered roles to replicate data and workloads across multiple servers. If one server fails, another server in the cluster can take over its workload with minimal disruption.
Continuous availability clusters
On the other hand, continuous availability (CA) clusters are designed to provide zero downtime for applications and services. CA clusters typically use a technique called synchronous replication to ensure that data is always available on all servers in the cluster. If one server fails, another server in the cluster can take over its workload immediately, without any interruption to users.
Synchronous replication in CA clusters
Synchronous replication works by writing all data to the primary server and then waiting for the data to be acknowledged by the secondary server before returning a response to the client. This ensures the data availability on both nodes.
This technique is often used for applications and services that require zero downtime, such as financial trading systems and mission-critical databases. However, synchronous replication can also introduce latency, as the client must wait for the data to be acknowledged by the secondary server before receiving a response.
Other failover cluster types
Besides HA and CA clusters, there are a few other types of failover clusters, including:
- Stretch clusters: Stretch clusters span over two or more data centers. They usually use synchronous replication and have high-speed and low-latency connections as well as excellent reliability and recovery design.
- Geo-distributed clusters: Geo-distributed clusters are used to provide global or large regional service for apps, systems, and services. The nodes in a geo-distributed cluster spread across multiple geographic regions. Geo-distributed clusters also typically use asynchronous replication to replicate data across the different regions. They can use content delivery network (CDN) networks or other forms of edge computing to reduce latency and improve performance.
Hybrid failover clusters: Virtual machines, physical data centers, and private and public clouds
Failover clusters can also combine physical servers with virtual machines (VMs) or private and public cloud infrastructures. These hybrid clusters are becoming increasingly popular as VMs and cloud services allow companies to access hardware and virtualization technologies without the upfront costs of buying the hardware or the software or maintaining it.
Additionally, by combining the increased security of physical on-premises or private cloud nodes with the flexibility and availability of VMs, companies can create hybrid failover clusters that combine the best of both worlds.
Usually, the backend and critical components of the cluster are deployed on physical data centers or private cloud nodes, while the customer-facing or public systems, apps, and services run on VMs.
Another approach to deploy hybrid failover clusters is to use a hypervisor to create a virtual cluster on top of a layer of physical servers. This approach can provide the most flexibility and scalability, but it can also be the most complex to implement.
How does a failover cluster work?
The way failover cluster technology works depends on the types of failover clusters deployed. However, there are several key common ground technologies worth mentioning including shared storage, clustered roles, synchronous replication, heartbeat monitoring and quorum voting.
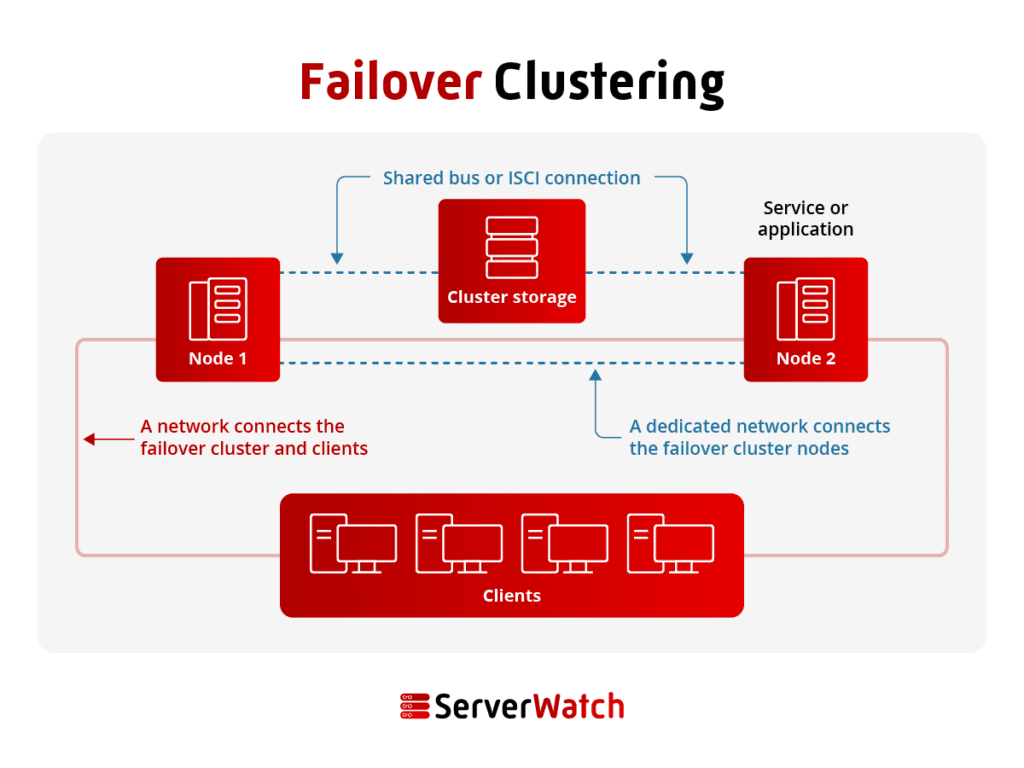
Shared storage and clustered roles
HA clusters usually use shared storage and clustered roles to replicate data and workloads across multiple servers.
While not all failover cluster systems use shared storage, those that do have a shared storage device are accessible to all of the servers or nodes in the cluster. This ensures that all of the servers have access to the same data, even if one server fails.
On the other hand, clustered roles are applications and services that can be moved from one node in the cluster to another node without disrupting the application or service.
Heartbeat monitoring
Heartbeat monitoring is a type of replication method technology which is used to monitor the nodes’ health and performance. With heartbeat monitoring, each node in the cluster is constantly sending out a “heartbeat” over a dedicated network link advertising its status and availability.
Quorum voting
Quorum voting is a process used in failover cluster systems to ensure that there is always a majority of servers or nodes in the cluster that are operational.
Quorum voting works by assigning each server in the cluster a vote. The cluster must have a quorum, which is a minimum number of votes required for it to operate.
Parameters for quorum voting can be configured to different settings. For example, a cluster with five nodes may require a quorum of four nodes.
Synchronous replication
CA clusters, designed for zero downtime, generally use synchronous replication to ensure that data is always available on all servers in the cluster. Stretch clusters and geo-distributed clusters also typically use synchronous replication.
Hybrid clusters may use different types of tools and technologies, especially when built with services and infrastructure offered by top virtualization vendors.
Practical applications of failover clusters
Let’s look at several practical modern applications for failover clusters that are commonly used in our digital world.
Ongoing availability of mission critical applications
Fault-tolerant systems are a necessity for computers used in online transaction processing (OLTP) systems. OLTP, which demands 100% availability, is used in airline reservations systems, electronic stock trading, and ATM banking, for example.
Many other types of organizations also use either CA clusters or fault-tolerant computers for mission-critical applications, such as businesses in the fields of manufacturing, logistics, and retail. Applications include e-commerce, order management, and employee time clock systems.
Disaster recovery
Failover clusters are also used for disaster recovery. If one data center fails, applications and services can be switched to another data center without disrupting users. This can help businesses to recover from a disaster quickly and minimize downtime.
Of course, it’s highly advisable for failover servers to be housed at remote sites in the event of a regional disruption or disaster such as a fire or flood. By stretching failover clusters, organizations can replicate among multiple data centers. If a disaster strikes at one location, all data continues to exist on failover servers at other sites.
Data and analytics
The data and analytics industry which operates in every industry today has sophisticated operational demands, is often rife with strict compliance and governance rules, and must manage and analyze significant amounts of data. In these environments, the characteristics of failover clusters are beneficial for those working with the entire data lifecycle.
Edge computing
Edge computing is a distributed computing paradigm that brings computation and data storage closer to the end user. Failover clusters can be used to deploy and manage edge computing applications and services.
Other practical uses of failover clusters include web applications that need to be highly scalable to handle spikes in traffic, internet of things (IoT) applications that require edge computing, and industries such as fintech that manage real-time low latency information but demand high levels of backup and redundancy.
Challenges of failover clusters
There are several downsides to failover cluster technology, despite their many established benefits. The most significant cons of the technology are linked to the skills required and the costs.
Cost
The costs of failover clusters can be significant if an enterprise wants to use its own hardware and software. Fortunately, with the rise of cloud computing and virtualization, hardware, software, and maintenance and management costs have decreased significantly.
Management
Similarly, companies that want to build sophisticated failover clusters but do not have the in-house talent that these systems demand can offload and outsource the management of the technology. This will represent an increase in costs but these tend to be significantly lower when compared with the expenses of having your own specialized team of experts.
However, even when offloading business-critical failover cluster management and operation processes, enterprises still need to have at least a small group of talented workers to make sure the systems are performing as they should. These talent barriers are without a doubt the greatest roadblock for those wanting to deploy a failover cluster.
Security, compliance, and reliability
Additionally, the talent issue will also affect performance, security, compliance, and privacy. A failover cluster that is not properly built, customized, and configured is at a high risk of creating disruptions. Failover clusters also expand the digital attack surface of a business, therefore increasing the chances of cybercriminals finding a vulnerability to exploit.
Top failover cluster vendors
There are several failover cluster vendors that are recognized in the industry as the top providers.
VMware
Among the virtualization products available, VMware offers several virtualization tools for VM clusters. vSphere vMotion provides a CA architecture that exactly replicates a VMware VM and its network between physical data center networks.
Microsoft
Microsoft offers a variety of failover cluster solutions, including Windows Server Failover Clustering, SQL Server Failover Clustering, and Exchange Server Failover Clustering. Microsoft’s failover cluster solutions are widely used by businesses of all sizes and they are known for their reliability and ease of use.
Red Hat Linux Failover Clusters
Operating system makers other than Microsoft also provide their own failover cluster technologies. For example, Red Hat Enterprise Linux (RHEL) users can create HA failover clusters with the Red Hat Enterprise Linux High Availability Extension (RHEV). Red Hat’s failover cluster solutions are known for their open-source nature and their flexibility. They can be used to protect a wide range of applications and databases and they can be deployed in a variety of environments, including on-premises, cloud, and hybrid.
Oracle
Oracle offers a variety of failover cluster solutions, including Real Application Clusters (RAC), Oracle Database Clusterware, and Oracle GoldenGate. Oracle’s failover cluster solutions are designed for high-performance and mission-critical applications. They are used by many of the world’s largest companies, including financial institutions, government agencies and telecommunications companies.
Other failover cluster vendors
Other popular 2023 failover cluster vendors and solutions include IBM PowerHA SystemMirror, NetApp MetroCluster, Rocket iCluster, and Veritas InfoScale.
Bottom line: Failover clusters keep your business running smoothly
From latency to troubleshooting environments, configuring shared storage and clustered roles, and monitoring systems, failover clusters are difficult to implement and manage. Industry best practices such as using certified solutions, services, hardware and securing expert talent can help solve these challenges. Companies should also have a solid failover cluster strategy and test and monitor their systems constantly to ensure performance and system integrity.
Despite the barriers, failover clusters are an excellent solution for business-critical systems, offer strong backup and recovery insurance, and can increase availability and drive the latest innovation in technology.
Protect your data against theft, loss, or damage with one of the best server backup solutions, selected and reviewed by our experts.