



A data lakehouse is the data management paradigm combining data warehouse and data lake capabilities into a unified platform for optimizing structured and unstructured data storage.
While data warehouses have long been the answer to storing structured data, the explosion of data in recent decades led to data lakes storing vast amounts of unique and unstructured data types.
Only recently have the leading database software and storage management companies started to develop and market the newest hybrid solution for managing the universe of data an organization possesses.
The Evolution of the Data Pipeline: Warehouses to Lakes
The development of data lakehouses results from an evolution in how enterprise organizations and data centers manage expanding amounts and different types of data.
Before understanding data lakehouses, organizations must first be familiar with their predecessors: data warehouses and data lakes.
What is a Data Warehouse?
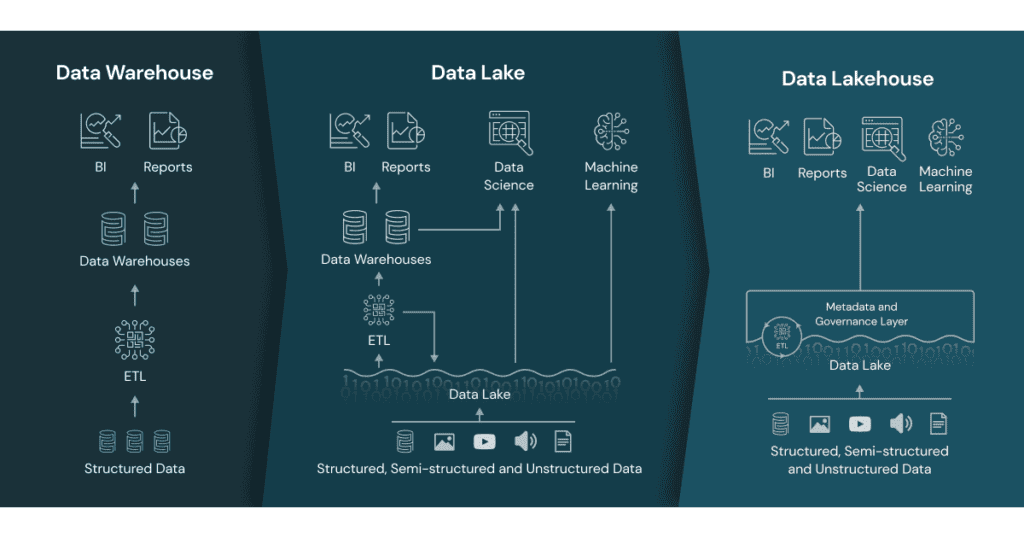
Starting in the 1980s, data warehouses have always been purpose-built repositories for storing structured data used for reporting and business intelligence (BI). Standard data warehouses receive external and operational data filtered through extract, transform, and load (ETL) software, which efficiently transforms and stores the structured data in a repository of the same data format.
What is a Data Lake?
Almost a decade ago, Pentaho CTO James Dixon coined the term “data lake” to describe a repository storing data in its raw format. Unlike data warehouses which store structured data, data lakes hold the spectrum of structured, semi-structured, and unstructured data and types.
While increasingly popular for many enterprise use cases, data lakes are optimal for validation for data science applications. In contrast, other data lake contents move through an ETL solution for use in a data warehouse or real-time database.
Compare top data warehousing solutions with Druid vs Dremio on TechRepublic.
Problems with Data Warehouses and Data Lakes
Data Warehouse Problems: Rigid and Proprietary
Because data warehouses abide by strict proprietary formats, they fail to support the mix of new and different data types, including video, audio, streaming, and deep learning models like artificial intelligence (AI) and machine learning (ML).
This inability to manage unstructured data pushed enterprise organizations to extract and store excess data for what would become data lakes.
Data Lake Problems: Wild and Unreliable
Though they offer unstructured data storage, data lakes are known for being unreliable data swamps. Relative to the efficiency expected of data warehouses, data lakes tend to perform poorly and struggle to support BI applications.
Using Both Data Warehouses and Data Lakes: Duplication
Since the arrival of data lakes, organizations have attempted to leverage both warehouse and lake capabilities through two different systems and teams. Traditional IT professionals and database administrators manage the warehouse while data scientists focus on harnessing the lake’s potential.
This coexistence of data warehouses and lakes for organizations often leads to data duplication, replicated processes, and increased costs. The latest paradigm for data administrators to address these concerns is the data lakehouse.
Learn how Databricks Helps Partners Tap Its Lakehouse Platform for Data and AI Services on Channel Insider.
What is a Data Lakehouse?
A data lakehouse features components from both data warehouses and data lakes to give administrators a single store of data for BI, data science, deep learning, and streaming analytics. With data lakehouses, administrators can manage the spectrum of raw data with an interface and data governance similar to traditional data warehouse management.
Commonly accepted capabilities of data lakehouses include:
- All data (structured, semi-structured, and unstructured) gets stored in a single repository
- End-to-end streaming offering real-time insights from the data repository
- Direct access for administrators for read or write operations on data
- Decoupling of compute and storage for scalability and multi-use
- Schema support for establishing data governance
- Indexing and data compaction for increasing query speed
- Atomicity, concurrency, isolation, and durability (ACID) transaction support
By consolidating multiple systems – data warehouse(s) and data lake(s) – into a data lakehouse, organizations can simplify the administration of schema and data governance, and reduce redundancy, replicated processes, and overhead costs. Like data lakes of the cloud era, data lakehouses offer low-cost storage and extensive scalability.
Top Data Lakehouse Vendors
| Cloudera | Couchbase |
| Databricks | DataStax |
| Dremio | IBM |
| Neo4j | Redis |
| Snowflake | TigerGraph |
See why IBM makes ServerWatch’s Top Data Fabric Solutions.
Data Lakehouses: The Best of Both Worlds
Data lakehouses offer a bridge for collaboration between an organization’s data management stakeholders. Though a newer concept, the hope for a unified solution for managing structured and unstructured data is alive. In the budding market, several notable vendors are building out their data lakehouse capabilities.
Keep an eye out for what’s to come in the next generation of data management solutions.
Round out this look at data lakehouses with the five things you need to know according to TechRepublic:
Additional Coverage
- Databricks vs Snowflake | TechnologyAdvice
- Top DataOps Tools | IT Business Edge
- Best predictive analytics tools and software | TechRepublic
- Best MLOps Tools & Platforms | IT Business Edge
- Data Center Consolidation Accelerates with CyrusOne, CoreSite Deals | Channel Insider
- Databricks Acquires 8080 Labs | TechnologyAdvice
- Databricks Turns Data Into Billions | InternetNews