


So, the loop for paging is done, all the pages are written now (an example page in the image at right), so the next step is closing code to take care of letting me know what happened, so this is just a total page saved to a file as a log, really, but is output in html.
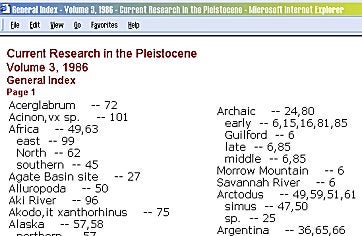
totlines = totlines + (series * 80) + paging totpages = series + 1 |
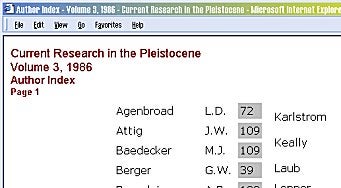
This coding is then modified for creating the author index by changing output and field names, with separately developed pages for bibliography. The content itself is plain html with few images, as content is added the tables are updated and subsequent builds will have the new information linked in. If the content had been already in electronic format, the project would be finished in five days for the amount of work. The editing is almost as slow as manual entry, so it’s the bottleneck on this particular job.
Of course this is just the publishing end of the process, yet by establishing the databases with the information, future content manipulation is easy. Editing field separators into lists so they can be imported into spreadsheets and databases as fields is a key issue for this type of work, parsing fields with software is not as reliable as a human operator in this case, too many variables in the content, so using that expensive time to establish the data structure is as important as its’ quality. Since quality is very important to academic content, this system really helps to organize and validate the data as it gets processed and yet is pretty easy to develop.
The next page has the entire code, the displayed code was tested was copied and pasted into a text editor, saved as an asp file and run.